The question seems to be straightforward: “what bad stuff happens when after somebody develops an intracerebral hemorrhage, and how will I know whether that will also happen to me now that I have one”? The answer is, as always, “it depends”. It depends on how you actually specify the question. What does “bad stuff” mean? Which “when” are you interested? And what are your personal risk factors? We need all this information in order to get an answer from a clinical prediction model.
The thing is, we also need a good working clinical prediction model – that is it should distinguish those who develop the bad stuff from those who don’t, but it should also make sure that the absolute risks are about right. This new paper (project carried by JW) discusses all ins and outs when it comes to the current state of affairs when it comes to predictions. Written for neurologist, some of these comments and points that we rise will not be new to methodologists. But as it is not a given that methodologist will be involved somebody decides that a new prediction model needs to be developed, we wrote it all in up in this review.
The paper, publishes in Neurological Research and Practice, has a couple of messages:
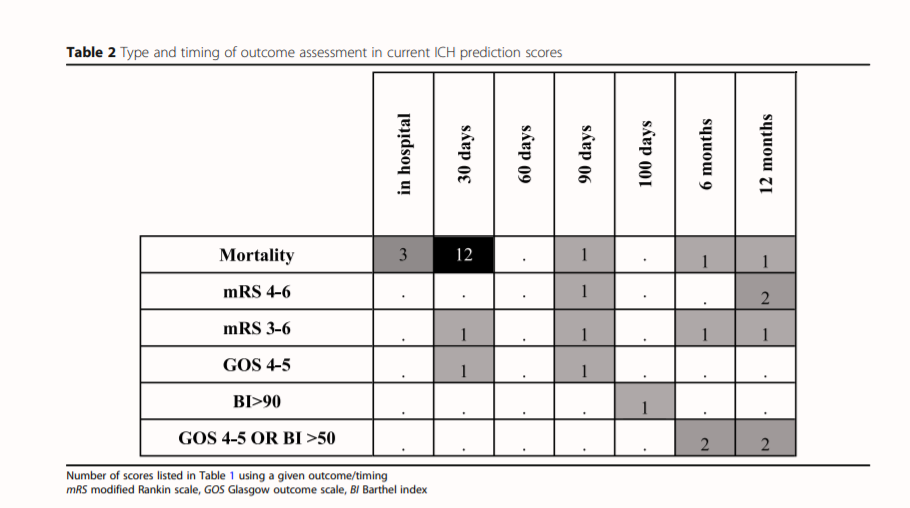
- The number of existing prediction models for this disease is already quite big – and the complexity of the models seem to increase overtime, without a clear indication that the performance of these models gets better. A lot of these models use different definitions for the type of outcome, as well as the moment that the outcome is assessed – all leading to wildly different models, which are difficult to compare.
- The statistical workup is limited: The performance is often only measured in a simple AUC- calibration and net benefit is not reported on. Even more worryingly, external validation not always possible, as the original publications do not provide point estimates.
- Given the severity of the disease, the so-called “withdrawal of care bias” is an important element when thinking and talking about prognostic scores. This bias, in which those with a bad score do not receive treatment can lead to a self-fulfilling prophecy type of situation in the clinic, captured in the data.
In short – when you think you want to develop a new model, think again. Think long and hard. Identify why the current models are working or are not working. Can you improve? Do you have the insights and skill set to do so? Really? If you think so, please do so, but just don’t add another not so useful prediction model to the already saturated literature.