
I wrote a series of emails in the last couple of weeks I never thought I would need to write: I gave the final okay on the wording of a retraction notice for one of the papers that I have worked on during my time in Berlin. Let me provide some more insight than a regular retraction notice provides.
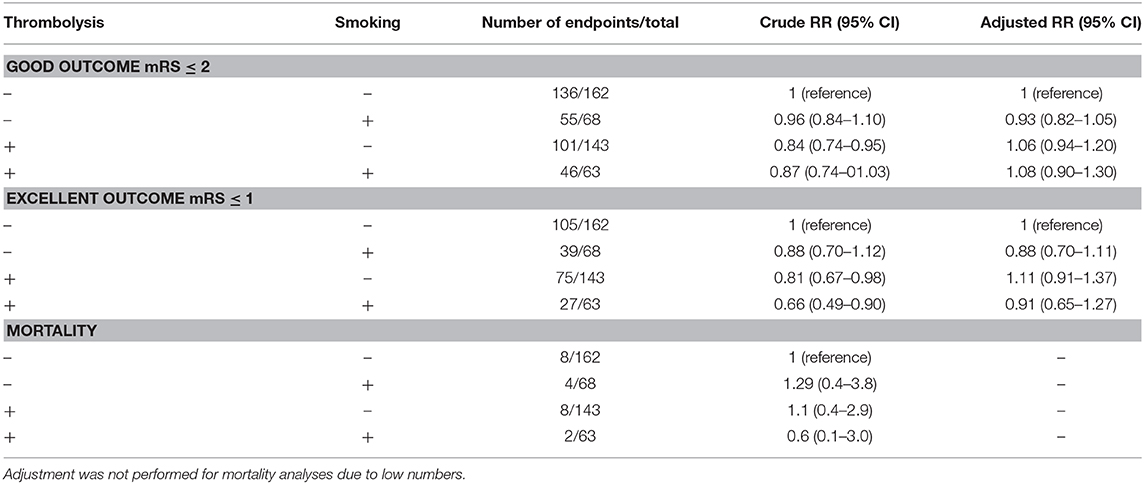
Let’s start with the paper that we needed to retract. It is a paper in which we investigate the so-called smoking paradox – the idea that those who smoke might have more beneficial effects from thrombolysis treatment for stroke. Because of the presumed mechanisms, as well as the direct method of treatment delivery IA thrombolysis is of particular interest here. The paper, “The smoking paradox in ischemic stroke patients treated with intra-arterial thrombolysis in combination with mechanical thrombectomy–VISTA-Endovascular”, looked at this presumed relation, but we were not able to find evidence that was in support of the hypothesis.
But why then the retraction? To study this phenomenon, we needed data rich with people who were treated with IA thrombolysis and solid data on smoking behavior. We found this combination in the form of a dataset from the VISTA collaboration. VISTA is founded to collect useful data from several sources and combine them in a way to further strengthen international stroke research where possible. But something went wrong: the variables we used did not actually represent what we thought they did. This is a combination of limited documentation, sub-optimal data management, etc etc. In short, a mistake by the people who managed the data made us analyze faulty data. The data managers identified the mistake and contacted us. Together we looked at whether we could actually fix the error (i.e. prepare a correction to the paper), but the number of people who had the treatment of interest in the corrected dataset is just too low to actually analyze the data and get to a somewhat reliable answer to our research question.
So, a retraction is indicated. The co-authors, VISTA, as well as the people on the ethics team at PLOS were all quite professional and looking for the most suitable way to handle this situation. This is not a quick process, by the way – from the moment that we first identified the mistake, it took us ~10 weeks to get the retraction published. This is because we first wanted to make sure that retraction is the right step, get all the technical details regarding the issue, then we had to inform our co-authors and get their formal OK on the request for retraction, then got in touch with the PLOS ethics team, then we had two rounds of getting formal OK’s on the final retraction text, etc, and only then the retraction notice went into production. The final product is only the following couple of sentences:
After this article [1] was published, the authors became aware of a dataset error that renders the article’s conclusions invalid.
Specifically, due to data labelling and missing information issues, the ‘IAT’ data reflect intra-arterial (IA) treatment rather than the more restricted treatment type of IA-thrombolysis. Further investigation of the dataset revealed that only 24 individuals in the study population received IA-thrombolysis, instead of N = 216 as was reported in [1]. Hence, the article’s main conclusion is not valid or reliable as it is based on the wrong data.
Furthermore, due to the small size of the IA-thrombolysis-positive group, the dataset is not sufficiently powered to address the research question.
In light of the above concerns, the authors retract this article.
All authors agree with retraction.
https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0279276
Do you know what is weird? You know you are doing the right thing, but still… it feels as if it is not the sciency thing to do. I now have to recognize that retracting a paper, even when it is to correct a mistake without any scientific fraud involved, triggers feelings of anxiety. What will people actually think of me when I have a retraction on my track record? Rationally, I can argue the issue and explain why it is a good thing to have a retraction on your record when it is required. But still, those feeling pop up in my brain from time to time. When that happens, I just try to remember the best thing that came out of this new experience: my lectures on scientific retractions will never be the same.
















{kind=link}